
Be Semantic: How to Install Microdata
February 1st, 2012 by
Search engines are designed to do one thing — make sense of the various documents found on the Web. Originally using just on-page factors like content and meta information contained in specialized tags, search engines moved to analysis of links in the late 90’s with the advent of the PageRank algorithm. This new method treated links as “votes” for websites, using anchor text and website clout to determine what is relevant to a search query. Recently, though still relying on links as the main source for determining a page’s worth, search engines and other Internet spiders are returning to on-page factors to find information that’s meaningful to users.
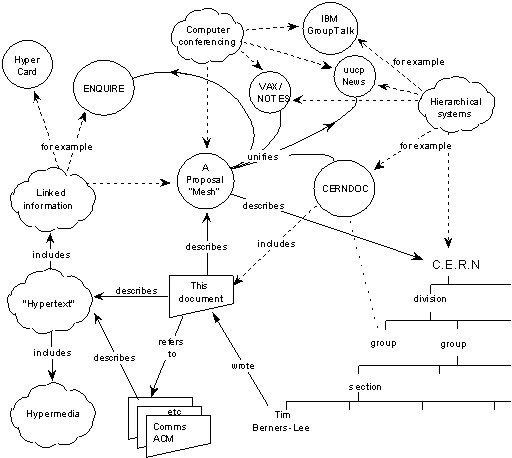
“New” On-Page Meta
These “new” on-page factors are the culmination of work dating back to the beginning of the modern Internet. The original diagram showing the basics of how the Web would work devotes much of its space to showing the connections between pages, but one corner lays the foundation for what is now known as the semantic web. This image shows a few of the basic properties in the semantic web: rel=author and other relationship markups, Schema’s breadcrumbs and on-page descriptions, and the hCard microformat.
Each of these more recent formats are designed to expand on what’s called POSH — “plain old semantic html” — that is, using <p> tags for paragraphs, <ul> or <ol> tags for lists, and <table> tags for tables of data instead of as layout and design elements. The two most common microdata formats, Schema and Microformats, are each based on pure HTML, codifying the use of HTML5’s itemscope and HTML4’s class and ID attributes respectively. In this way, microformats seek to make standard web coding easier for computers to find and use the various data visible on the page.

Implementing Microdata
The four most common formats of microdata: XFN, OpenGraph, Microformats, and Schema, make an alphabet soup unwelcoming to newcomers. Part of microdata’s charm is its ease of installation. But while some ways to tell search engines and other scrapers how to index a page are somewhat more arcane, microdata sits on top of the code, easily being added to existing pages.
Microformats and XFN require relatively little extra knowledge, while Schema and Open Graph assume a little bit of forward-thinking HTML5.
Microformats & hReview
hReview, like many compound Microformats, is based around hCard, which was designed to mimic the electronic business card format vCard. With hReview, you can easily mark up reviews to show in Google’s SERPs using standardized classes and IDs.
In order to do this, there are two steps to the markup. The first is the hReview-Aggregate markup which gives the data shown in the SERP: number of reviews and overall ranking. The second are the actual reviews. Both use hCard to describe about or by whom the review is written.

Here’s the hReview-Aggregate code from that page:
<div>
<h1>Patient Reviews for Columbus, Ohio Plastic Surgeon<br>
<span id="donaldson-plastic-surgery">
<span>Donaldson Plastic Surgery – Dr. Jeffrey Donaldson</span>
<span>
<span><span title="4661 Sawmill Rd #100"></span></span>
<span><span title="Columbus"></span></span>
<span><span title="OH"></span></span>
<span><span title="43220"></span></span>
</span>
</span></h1>
<p>
<span>
<span><span title="4.8"></span></span>
<span><span title="5"></span></span>
<span><span title="20"></span></span>
</span>
</p></div>
Much of this example code won’t show, which is against Google’s rich snippets documentation; however, as you can see, the snippet shows in the SERPs. The class=”value-title” syntax follows the microformat specs from their site. But should invisible content be used? Or is it spam? More on that later.
For the single hReview, the code is clear and most sections are visible. Again, use the value-title syntax to hide any data that’s not meaningful to the user.
<div>
<span><span><span title="Donaldson Plastic Surgery - Dr. Jeffrey Donaldson"></span></span><br>
<span><span title="Tummy Tuck, Columbus, OH"></span><br>
<span>
<p>DESCRIPTION</p>
<p><em>- <span>DM</span> / Columbus, OH </em></p>
<p><span><span title="4.8"></span></span></p></span></span></span></div>
XFN & rel=author
Like microformats, there are other microdata formats that use HTML 4 entities, which keeps the code accessible to most levels of website owners. XFN establishes personal relationships between pages on the Internet and is one of the easiest microformats to install. Prepackaged in many basic WordPress installations, XFN has one major use: establishing your identity using rel=author.
Using the XFN markup rel=”me”, which relates web pages about someone with social media and other profiles, and the microformat rel=”author”, which associates posts with other web pages about the author, you can let Google and other spiders know who wrote the post. While Google requires further steps and whitelisting to show up in the SERPs,
For an example, take a look at our authorship markup.
<a title="Posts by Julia Ramsey" href="https://www.searchinfluence.com/author/jramsey/" rel="author">Julia Ramsey</a>
This links to Julia’s author archive page, which in turn has a link to her Google+ profile.
<a href="https://plus.google.com/u/1/104804485354016147497?rel=author" rel="me"><img src="https://www.searchinfluence.com/wp-content/themes/si-dec10/images/g-plus-icon-32x32.png" alt="Find Julia Ramsey on Google+" width="30" /></a>
There’s some other magic going on, but overall the rel=”me” XFN markup shows who wrote the page and connects it to a social network to grab more information.
Open Graph
Moving from connecting with to interacting with social networks, Open Graph is meta information for Facebook. While much of the Semantic Web is about marking up body content, Facebook’s meta information is in the header as tags.
Using our site as an example:
<meta property='og:title' content='SOPA Dope – Today’s “Blackout”, Tomorrow’s SEO Audit' />
<meta property='og:site_name' content='Website Promotion Company: Search Influence - Economical SEO New Orleans, LA SEO / Internet Marketing' />
<meta property='og:url' content='https://www.searchinfluence.com/2012/01/sopa-dope-todays-blackout/' />
<meta property='og:type' content='article' />
<meta property='fb:app_id' content='197784673584291'>
<meta property="og:image" content="http://graphics.nytimes.com/images/promos/politics/blog/23thompson-nbc.jpg" />
<meta property="og:locale" content="en_US" />
There are 7 required tags, mostly named logically. Two that are confusing are og:type and og:locale. The first should be “article” for most pieces of content. The “article” type is for anything that’s a single written post. Necessary, and not always included in Open Graph plugins, is og:locale, which refers to the language and location of the site.
Schema for Music
Finally, we come to Schema, the search engines’ attempt to standardize semantic microdata. Schema is deeper and more customizable than any of the other formats, however at the expense of clarity. It uses the itemprop, itemscope, and itemtype attributes from HTML5.
Of all places to find a modern web example, MySpace’s band profiles use schema for music. Check out the music player on this band’s page.
The code’s a little less clear because of the flexibility of Schema, but you’ll see by looking at the itemprop attribute that there is a wide variety of meta information categorized and sectioned in that small block of text. In the SERPs, it outputs as a rich snippet, linking to the individual song pages. Needless to say, while extremely niche, this power is invaluable for musicians and bands. All of Schema is this niche, but the benefits are massive, as seen here:

Is it Spam?
There comes a point where a marketer could easily see the potential for abuse. Hidden data, which we touched on before, is only one aspect. Certainly, there can be hidden data that is misleading, however it’s clear that some data doesn’t need to be for the end-user. Google’s guidelines say to not hide any data that is a rich snippet, but for things like a strict star rating for a text post and repeating the subject of the review, there’s good reasons to hide structured content.
However, that hidden data quandary bleeds over to reviews in particular. No website owner is going to be happy about his own site showing his products and services to be low-quality. There is a clear directive for a business owner to cull bad reviews from his own site, and therefore the reviews may be less than perfectly accurate to their customers’ feelings. One way to avoid this would be to take advantage of user-generated content, with safeguards for malicious spam and abuse. Another would be to show accurate ratings based on a rubric, though that could easily become difficult for the website owner to get through.
For social meta data, often a marketer will use different descriptions and titles to target better on a given social network. This can be used for a sly bait-and-switch, similar to some ads that use a voluptuous beauty to make you click on a much less interesting post.
However, in most cases a high-powered sniff test and tummy check are all that are necessary to determine if something is spam. Certainly the tools would not be recognized by major search engines if semantic data were considered with the same level of scorn as some marketers have for pure meta keywords. If the reviews selected are glowing, why not give them all 5 stars? If the page is enhanced and not weakened by different social and search meta data, who would mind that?
The Internet is best served by a semantic, rich web. A vibrant search page, a web that’s easily crawlable for information, and a social experience enhanced by relationships and attribution are all at the core of microdata: make the most of your site today with these techniques.
[…] Be Semantic: How to Install Microdata, http://www.searchinfluence.com […]
Wonderful items from you, man. I have take into account your stuff prior to and you are just extremely fantastic. I actually like what you’ve received right here, really like what you’re saying and the way in which during which you are saying it. You make it enjoyable and you still take care of to stay it wise. I cant wait to read much more from you. That is really a great web site.